Python 的法宝函数¶
约 2359 个字 100 行代码 1 张图片 预计阅读时间 13 分钟
dir()查看内容help()查看功能,打开说明书
Tensor¶
PyTorch中的Tensor:PyTorch的 torch.Tensor 是一个多维数组,类似于NumPy的 ndarray,但额外支持GPU加速计算和自动求导,是构建神经网络的核心数据结构
- Tensor的 requires_grad 属性允许自动计算梯度,反向传播时无需手动实现链式法则。
- PyTorch的优化器(如torch.optim)、损失函数(如nn.CrossEntropyLoss)和模型层(如nn.Linear)均以Tensor为输入输出。
Pytorch 中的数据加载¶
张量(Tensor) 是核心数据结构,可以简单理解为多维数组。它是PyTorch中存储和操作数据的基本单位,支持自动求导、GPU加速等特性。
在PyTorch中,模型输入、输出和计算均基于张量。使用张量的原因包括:
- GPU加速:张量可转移到GPU(如tensor = tensor.cuda()),利用并行计算加速训练。
- 自动求导:张量支持记录计算图(requires_grad=True),便于反向传播梯度。
- 统一接口:PyTorch的神经网络层(如nn.Linear)要求输入为张量。
Dataset 类¶
- 作用:定义数据集的接口,负责读取单个样本及其标签。
- 核心方法:
__getitem__(self, index):根据索引返回一个样本及其标签(张量形式)。__len__(self):返回数据集的总样本数。
- 自定义Dataset:用户需继承
torch.utils.data.Dataset并实现上述方法。例如,处理图像数据时,可在__getitem__中加载图像、应用预处理(如归一化、数据增强),并返回张量格式的数据。 - 下面是一个例子
Pythonfrom torch.utils.data import Dataset from PIL import Image import os class Mydata(Dataset): def __init__(self,root_dir,label_dir): self.root_dir = root_dir self.label_dir = label_dir self.path=os.path.join(self.root_dir,self.label_dir) self.ing_path=os.listdir(self.path) def __getitem__(self, idx): img_name=self.ing_path[idx] img_item_path=os.path.join(self.root_dir,self.label_dir,img_name) img=Image.open(img_item_path) label = self.label_dir return img,label def __len__(self): return len(self.ing_path) root_dir="dataset/train" ants_label_dir="ants" bees_label_dir="bees" ants_dataset=Mydata(root_dir,ants_label_dir) bees_dataset=Mydata(root_dir,bees_label_dir)
使用官方的数据集¶
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose(
[torchvision.transforms.ToTensor(),
])
train_set=torchvision.datasets.CIFAR10(root='./dataset', train=True, transform=dataset_transform,download=True)
test_set=torchvision.datasets.CIFAR10(root='./dataset', train=False, transform=dataset_transform,download=True)
#print(test_set[0])
writer = SummaryWriter("P10")
for i in range(10):
img,target=train_set[i]
writer.add_image('test_set',img,i)
DataLoader¶
- 作用:包装
Dataset,提供批量加载、数据打乱、多进程加载等功能,生成可迭代对象。 - 关键参数:
batch_size:每个批次的样本数。shuffle:是否在每个epoch开始时打乱数据顺序(默认False)。- epoch(中文常译为“轮次”或“训练轮”)是模型遍历完整训练数据集一次的过程。它是训练过程中的基本单位,用于衡量模型对数据的学习次数。
num_workers:用于数据加载的子进程数(加速IO密集型操作)。drop_last:是否丢弃最后一个不完整的批次(当样本数不能被batch_size整除时)。sampler:自定义采样策略(如分布式训练中的DistributedSampler)。collate_fn:自定义如何将多个样本合并为批次(如处理变长序列)。
Tensorboard¶
TensorBoard 是 TensorFlow 的可视化工具,主要用于监控、分析和调试深度学习模型的训练过程。比如记录 loss
指定完 log 路径后会显示多次的数据(包括历史)并尝试拟合。
因此最好在每次训练的时候新建一个子文件夹来存放 log 数据,
实例代码:
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter("logs")
image_path = "data/train/ants_image/9715481_b3cb4114ff.jpg"
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL)
print(type(img_array))
print(img_array.shape)
writer.add_image("train2", img_array, 2, dataformats='HWC')
# y = 2x
for i in range(100):
writer.add_scalar("y=2x", 2*i, i)
writer.close()
Transforms¶
transforms.py 工具箱
torchvision.transforms 是 PyTorch 中用于数据预处理和数据增强的核心模块,主要用于图像数据的标准化、裁剪、翻转等操作,帮助提升模型泛化能力。
核心场景:
- 将原始数据(如 PIL 图像)转换为张量(Tensor)。(最常用)
- 在训练时增加数据多样性(Data Augmentation),防止过拟合。
- 对数据进行标准化(Normalization),加速模型收敛。
通俗而言:
* 每次使用前创建一个工具实例,通过这个工具实例来处理数据
常见的 Transforms¶
关注函数描述的输入和输出(见官方文档),注意函数的参数
1. ToTensor() 把数据类型转换成 Tensor
2. Normalize() 会对输入张量的每个通道执行以下计算,它的核心作用是通过对每个通道的像素值进行线性变换,将数据调整到特定的均值和标准差范围
Resize()将输入图像(PIL Image 或 Tensor)的尺寸调整为指定大小,强制统一所有输入图像的尺寸,以满足深度学习模型对固定输入尺寸的要求Compose的作用是将多个图像变换(transform)按顺序组合成一个整体。是PyTorch中构建图像预处理流水线的核心工具,通过将多个变换按顺序组合,确保数据在输入模型前经过规范化的处理。多个变换的顺序很重要,前一个的输出作为下一个的输入。
神经网络的基本架构¶
了解一下什么是卷积¶
那么……什么是卷积?
3b1b 的视频讲的非常好
数学上的定义
对于两个连续函数 \(f(t)\) 和 \(g(t)\),其卷积运算定义为:
\((f * g)(t) = \int_{-\infty}^{\infty} f(\tau)g(t - \tau) d\tau\)
对于两个离散序列 \(f[n]\) 和 \(g[n]\):
\((f * g)[n] = \sum_{m=-\infty}^{\infty} f[m]g[n - m]\)
这里以二维卷积举例,常见于图像处理 :
对于图像 \(I\) 和卷积核 \(K\):
\((I * K)[i,j] = \sum_{m}\sum_{n} I[i-m,j-n]K[m,n]\)
有一点需要明确的是:纯数学的卷积需要和反转,而 DL 中通常不需要
深度学习中的"卷积"运算实质是互相关运算(cross-correlation),与数学定义的卷积存在本质差异
严格数学卷积 = 互相关运算 + 核翻转180°
深度学习中的卷积运算¶
- 滤波器/Kernel:可学习的权重矩阵
- 特征图:卷积运算的输出结果
- 通道:输入数据的维度(如RGB图像的3通道)
输入特征图 \(X \in \mathbb{R}^{H×W×C}\),卷积核 \(W \in \mathbb{R}^{k×k×C×N}\):
- 在 pytorch 中的尝试
Pythonimport torch import torch.nn.functional as F input = torch.tensor([[1,2,0,3,1], [0,1,2,3,1], [1,2,1,0,3], [5,2,3,1,1], [2,1,0,1,1]]) kernel = torch.tensor([[1,2,1], [0,1,0], [2,1,0]]) #满足二维卷积的形式 input = torch.reshape(input,(1,1,5,5) ) kernel = torch.reshape(kernel,(1,1,3,3)) print(input.shape) print(kernel.shape) # 调用卷积层 output = F.conv2d(input, kernel,stride=1) print(output) # 步长改为2 output = F.conv2d(input, kernel,stride=2) print(output) # 外围填充的层数 output = F.conv2d(input, kernel,stride=1,padding=1) print(output)
然后我们可以看到三种卷积结果
Markdowntensor([[[[10, 12, 12], [18, 16, 16], [13, 9, 6]]]]) tensor([[[[10, 12], [13, 6]]]]) tensor([[[[ 1, 3, 4, 10, 8], [ 5, 10, 12, 12, 9], [ 7, 18, 16, 16, 11], [11, 13, 9, 6, 10], [14, 13, 9, 7, 4]]]])
通过互相关运算,使用可学习的滤波器在输入数据上滑动,提取局部特征模式。每个输出位置反映输入中特定模式的激活强度。
通过反向传播自动学习滤波器参数,网络能够自适应地发现对任务最有判别力的特征组合。
参数学习机制:
虽然未执行核翻转,但通过梯度下降算法:
网络会自动学习到与数学卷积等效的旋转滤波器参数。
通道是什么?¶
通道(Channel)是深度学习中对数据特征的维度抽象,在不同领域有不同表现形式:
| 数据类型 | 通道含义 | 示例 |
|---|---|---|
| 图像数据 | 颜色/特征通道 | RGB 图像的 3 通道分别对应红、绿、蓝分量 |
| 语音数据 | 频谱特征通道 | 不同频率区间的能量分布 |
| 文本数据 | 嵌入维度 | 词向量的不同语义维度 |
举个例子
输入一张彩色图片,它的的大小为 \(torch.Size([1, 3, 256, 256])\) 批次为 1,通道为 3,大小为 \(256\times 256\),这是输入的数据
我们希望输出是一个 64 个通道的张量,实际上就是用 64 个卷积核对原来的三个通道进行不同权重的采样,同于提取不同的数据信息
卷积层长这样 \(nn.Conv2d(3, 64, 3)\)
即输出通道是卷积核的个数
torch.nn¶
核心模块,提供了各种预定义的层,损失函数,优化工具等等。
卷积层¶
卷积层是为了提取数据的特征
卷积核的结构¶
对于一个将输入从 \(C_{in}\) 通道转换为 \(C_{out}\) 通道的卷积层:
- 每个输出通道对应一个形状为 \([C_{in}, k_h, k_w]\) 的3D卷积核
- 整个卷积层包含 \(C_{out}\) 个这样的3D卷积核
深度学习入门-卷积神经网络(一)卷积层 - 知乎
可视化展示
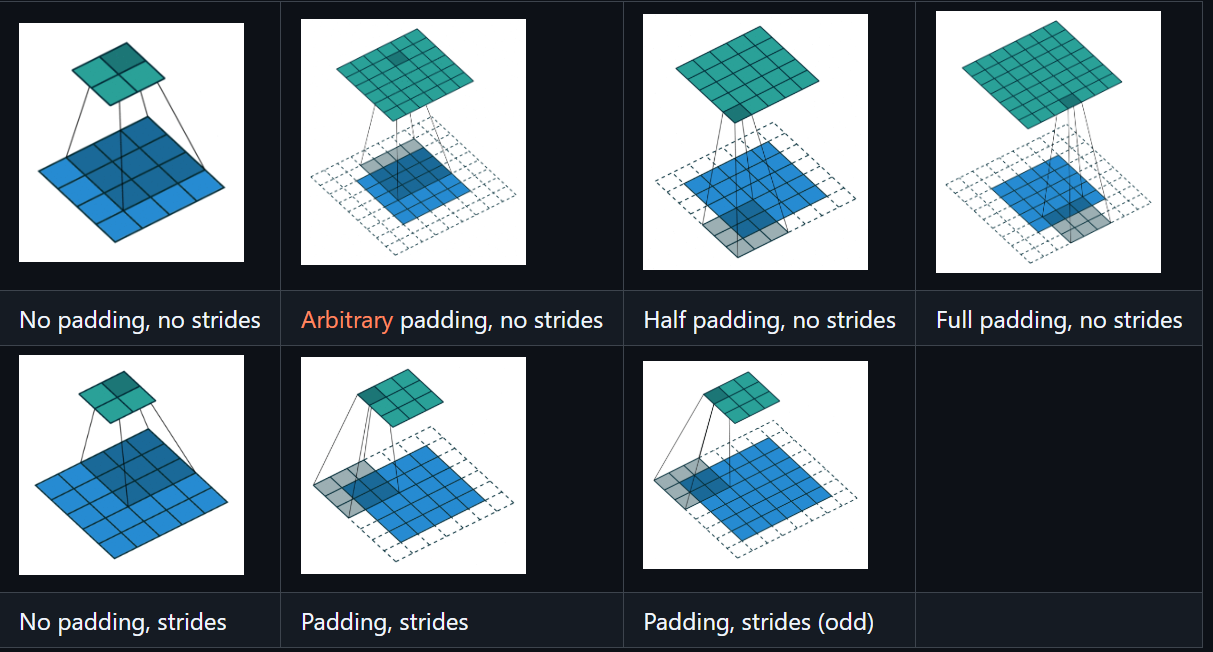
以Conv2d 为例,重要参数为如下:
* In_channels (int) – Number of channels in the input image
* Out_channels (int) – Number of channels produced by the convolution
* Kernel_size (int or tuple) – Size of the convolving kernel
* Stride (int or tuple, optional) – Stride of the convolution. Default: 1
* Padding (int, tuple or str, optional) – Padding added to all four sides of the input. Default: 0
更详细的见 api 文档
池化层¶
池化过程在一般卷积过程后。池化(pooling) 的本质,其实就是采样。Pooling 对于输入的 Feature Map,选择某种方式对其进行降维压缩,以加快运算速度。
本质是特征提取,用来压缩或者降维。要损失一部分信息。
* 池化层没有参数
以最大池化为例子,\(3\times3\) 的池化核就是对于数据每 \(3\times3\) 的数据取最大值,比如就可以把 \(9\times9\) 压缩为 \(3\times3\)
线性层¶
给定输入向量 \(\mathbf{x} \in \mathbb{R}^{d_{in}}\),权重矩阵 \(W \in \mathbb{R}^{d_{out} \times d_{in}}\),偏置 \(\mathbf{b} \in \mathbb{R}^{d_{out}}\):
| 特性 | 描述 | 典型应用场景 |
|---|---|---|
| 全局连接 | 每个输入节点连接所有输出节点 | 特征综合/分类决策 |
| 参数密集 | 参数量为 \(d_{in} \times d_{out} + d_{out}\) | 小规模特征处理 |
| 维度变换 | 灵活改变特征维度 | 网络瓶颈层设计 |
| 非线性基础 | 需配合激活函数使用 | 构建多层感知机 |
| # 模型的保存和模型的加载 | ||
| ## 保存的两种方法 | ||
| ## 加载的两种方法 | ||