什么是大模型¶
约 1149 个字 14 张图片 预计阅读时间 6 分钟
- 具有超大规模参数的与训练语言模型
- 主要为 Transformer 解码器架构
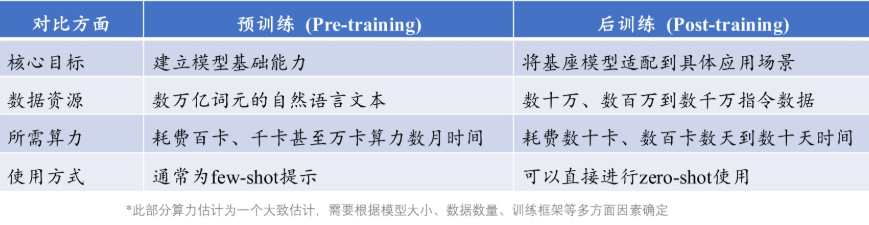
- 训练分为与训练和后训练,通过与训练建立模型的基础能力(利用海量的文本数据),再用大量的指令数据通过 SFT(监督微调,有标签数据进行针对性调整)和 RL(强化学习)等方式来后训练。最后投入下游运用。
- 预训练需要的算力更大。
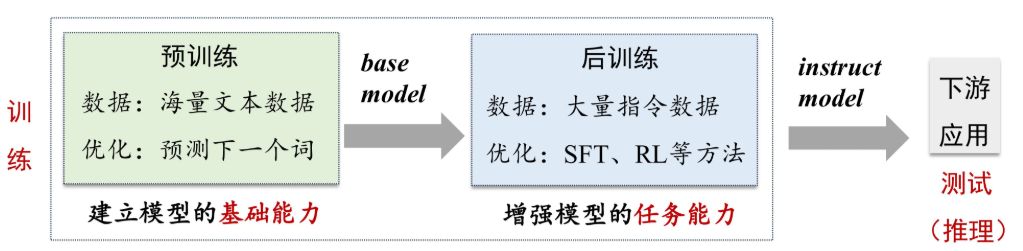
大语言模型构建概览¶
- 预训练:
- 使用与下游任务无关的大规模数据进行模型参数的初始训练
- 基于Transformer解码器架构,进行下一个词预测
- 数据数量、数据质量都非常关键
- 后训练:
-
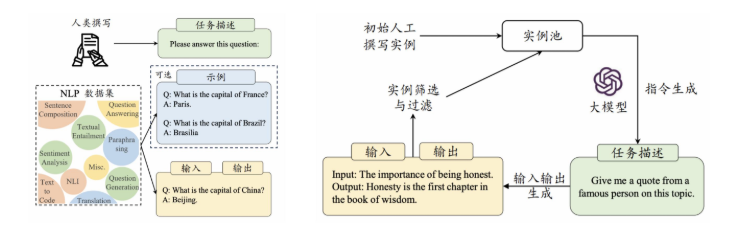
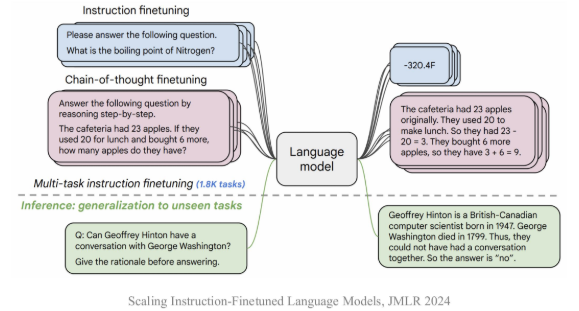
指令微调 (Instruction Tuning)
- 使用输入与输出配对的指令数据对于模型进行微调
- 提升模型通过问答形式进行任务求解的能力
-
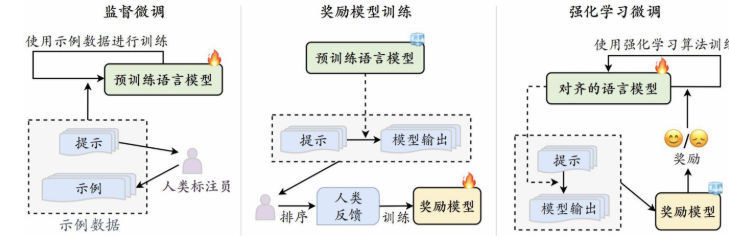
人类对齐(HumanAlignment)
- 将大语言模型与人类的期望、需求以及价值观对齐
- 基于人类反馈的强化学习对齐方法(RLHF)
扩展定理¶
- 什么是扩展定律
- 通过扩展参数规模、数据规模和计算算力,大语言模型的能力会出现显著提升
- 扩展定律在本次大模型浪潮中起到了重要作用
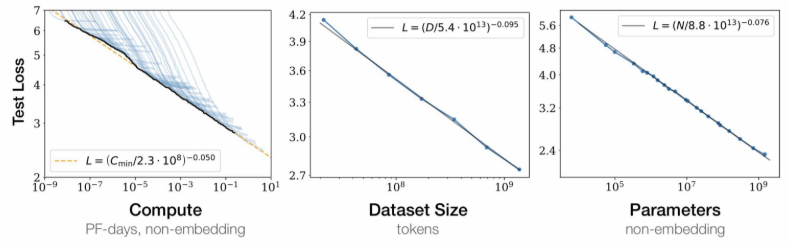
几种扩展定理 :¶
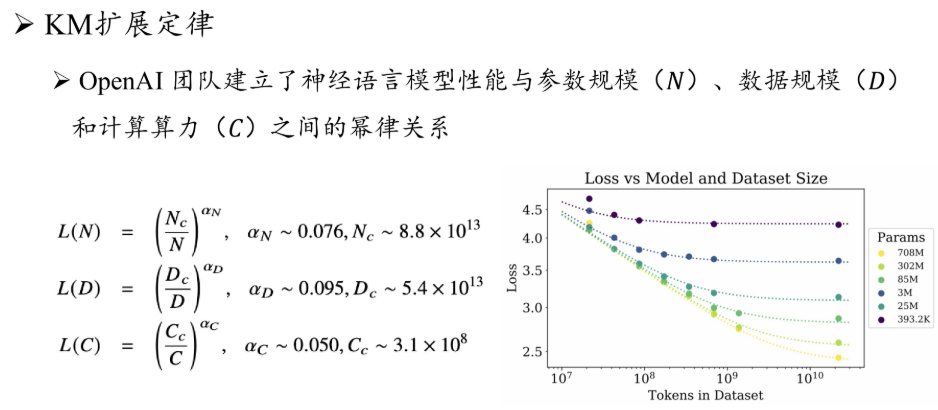
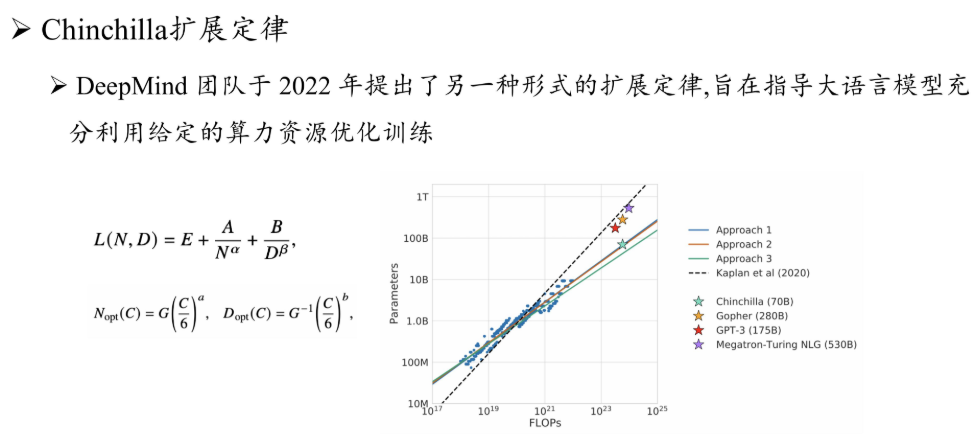
对扩展定理的思考¶
- 模型的语言建模损失可以分解成如下的形式

- 扩展定律可能存在边际效益递减
- 随着模型参数、数据数量的扩展,模型性能增益将逐渐减小
- 目前开放数据已经接近枯竭,难以支持扩展定律的持续推进
- 可预测的拓展
- 使用小模型性能去预估大模型的性能,或帮助超参数选择
- 训练过程中使用模型早期性能来预估后续性能
涌现能力¶
- 什么是涌现能力
- 原始论文定义:“在小型模型中不存在、但在大模型中出现的能力”
- 模型扩展到一定规模时,特定任务性能突然出现显著跃升趋势,远超随机水平
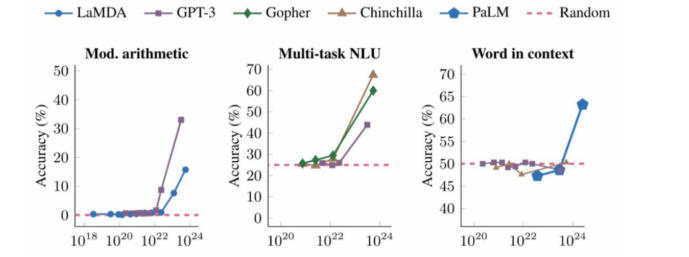
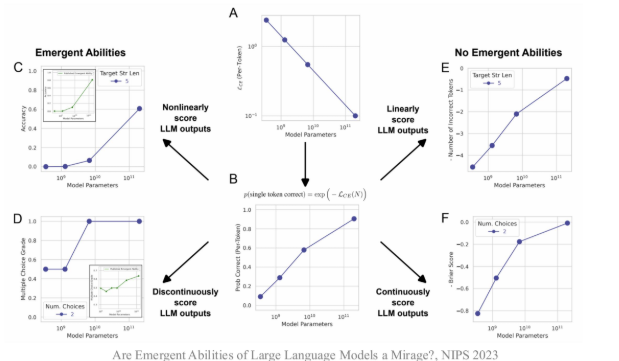
- 涌现能力可能部分归因于评测设置
- 代表性能力
- 指令遵循(InstructionFollowing)
- 大语言模型能够按照自然语言指令来执行对应的任务
- 代表性能力
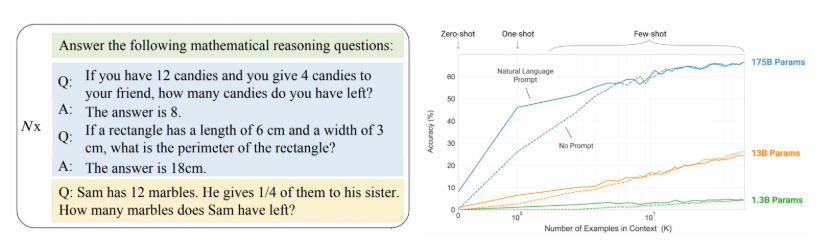
- 上下文学习(In-contextLearning)
- 在提示中为语言模型提供自然语言指令和任务示例,无需显式梯度更新就能为测试样本生预期输出
- RAG 技术可以提升文本的上下文处理能力,和 agent 都是近期的热点之一
- 涌现能力与扩展定律的关系
- 涌现能力和扩展定律是两种描述规模效应的度量方法
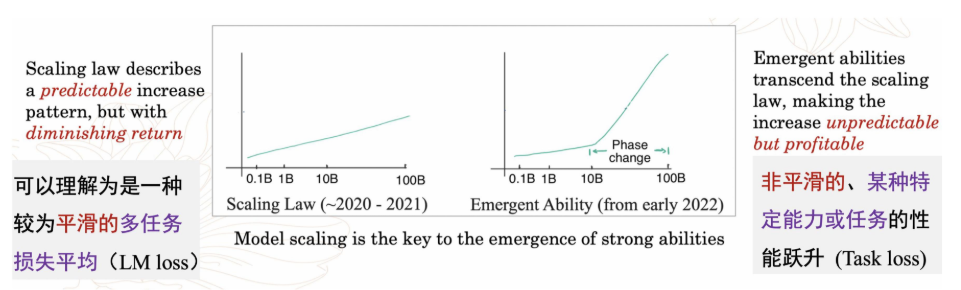
- 涌现能力和扩展定律是两种描述规模效应的度量方法
总结:¶
- 大模型核心技术
- 规模扩展:扩展定律奠定了早期大模型的技术路线,产生了巨大的性能提升
- 数据工程:数据数量、数据质量以及配制方法极其关键
- 高效预训练:需要建立可预测、可扩展的大规模训练架构
- 能力激发:预训练后可以通过微调、对齐、提示工程等技术进行能力激活
- 人类对齐:需要设计对齐技术减少模型使用风险,并进一步提升模型性能
- 工具使用:使用外部工具加强模型的弱点,拓展其能力范围
学习心得¶
现有大模型的技术在很多方向已经趋于成熟,但是深度学习尤其是神经网络导致的不可解释性导致很多技术的推进只能是尝试和经验总结,总结当前的技术特点,针对不足的地方用额外的方法弥补。比如希望大模型能够像人一样思考,就是用 RL 等技术后训练,针对长上下文的限制,用 RAG 来增强检索,总体上感觉目前的 LLM 还处于一个不停打补丁修正的环节,这可能还是因为 Transformer 这个结构的底层原因,也许未来的日子里我们能够找到更终极更底层的架构实现,让大模型达到超越人类思考的形式,而不是现在一样知识模仿人类的思考。