GPT 模型的发展历程¶
约 1146 个字 17 张图片 预计阅读时间 6 分钟
GPT系列模型成体系推进¶
- 2017年,谷歌提出Transformer
- 2018年,OpenAI提出GPT(1亿+参数)
- 2019年,GPT-2(15亿参数)
- 2020年,GPT-3(1750亿参数)
- 2021年,CodeX(基于GPT-3,代码预训练)
- 2021年,WebGPT(搜索能力)
- 2022年2月,InstructGPT(人类对齐)
- 2022年11月,ChatGPT(对话能力)
- 2023年3月,GPT-4(推理能力、多模态能力)
- 2024年9月,o1(深度思考能力提升)
- 2025年1月,o3(深度思考能力进一步增强)
可以说 GPT 的发展对现在的大模型发展起到了深远影响
GPT系列模型发展历程¶
- 小模型:GPT-1,GPT-2
- 大模型:GPT-3,CodeX,GPT-3.5,GPT-4
- 推理大模型:o-series
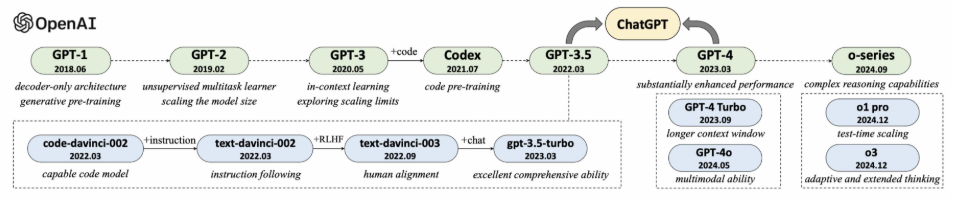
GPT 系列模型的技术演变¶
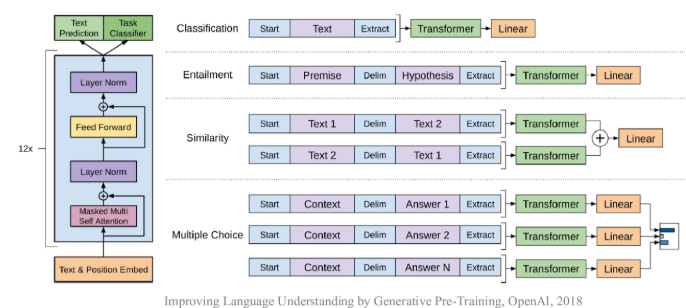
GPT-1 (1.1亿参数)¶
- Decode-onlyTransformer架构
- 预训练后针对特定任务微调
GPT-2(15亿参数)¶
- 将任务形式统一为单词预测
- Pr (output input, task)
- 预训练与下游任务一致
- 使用提示进行无监督任务求解
- 初步尝试了规模扩展
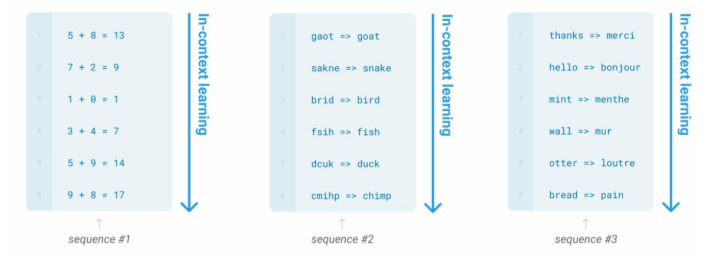
GPT-3¶
- 模型规模达到1750亿参数
- 涌现出上下文学习能力
CodeX¶
- 代码数据训练
- 推理与代码合成能力

WebGPT¶
大语言模型使用浏览器

InstructGPT¶
- 大语言模型与人类价值观对齐
- 提出RLHF算法(利用强化学习让大模型想人一样思考等等)

ChatGPT¶
- 基于InstructGPT相似技术开发,面向对话进行优化
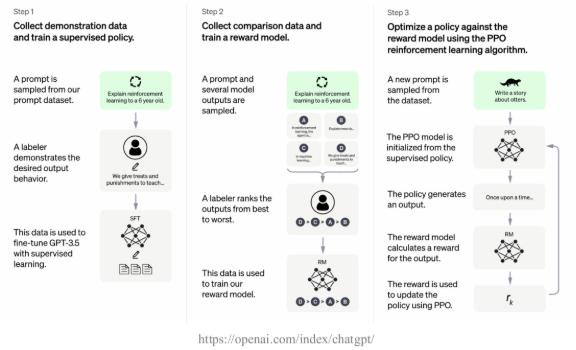
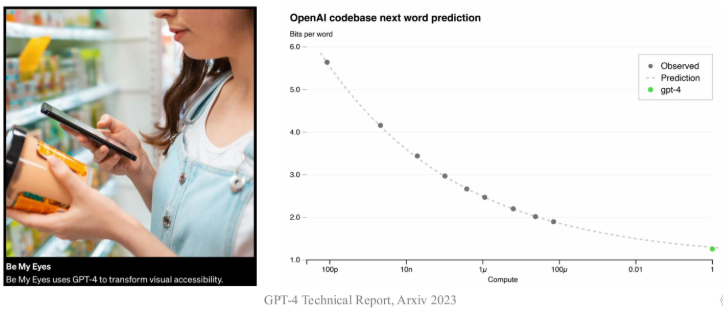
GPT4¶
- 推理能力显著提升,建立可预测的训练框架
- 可支持多模态信息的大语言模型
GPT-40¶
- 原生多模态模型,综合模态能力显著提升
- 支持统一处理和输出文本、音频、图片、视频信息

o系列模型¶
- 推理任务上能力大幅提升
- 长思维链推理能力
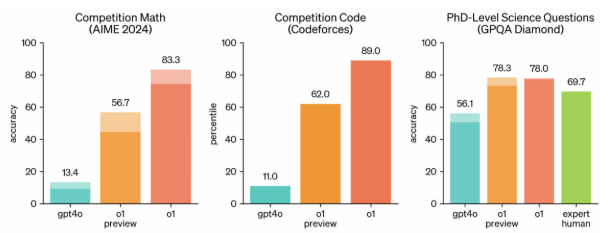
0-series¶
- 类似人类的“慢思考”过程

DeepSeek 系列模型的技术演变¶
- DeepSeek系列模型发展历程
- 训练框架:HAI-LLM
- 语言大模型:DeepSeekLLM/V2/V3、Coder/Coder-V2、Math
- 多模态大模型:DeepSeek-VL
- 推理大模型:DeepSeek-R1

- DeepSeek实现了较好的训练框架与数据准备
- 训练框架HAI-LLM(发布于2023年6月)
- 大规模深度学习训练框架,支持多种并行策略
- 三代主力模型均基于该框架训练完成
- 训练框架HAI-LLM(发布于2023年6月)
- 数据采集
- V1和Math的报告表明清洗了大规模的Common Crawl,具备超大规模数据处理能力
- Coder的技术报告表明收集了大量的代码数据
- Math的技术报告表明清洗收集了大量的数学数据
- VL的技术报告表明清洗收集了大量多模态、图片数据
- DeepSeek进行了重要的网络架构、训练算法、性能优化探索
- V1探索了scalinglaw分析(考虑了数据质量影响),用于预估超参数性能
- V2提出了MLA高效注意力机制,提升推理性能
- V2、V3都针对MoE架构提出了相关稳定性训练策略
- V3使用了MTP(多token预测)训练
- Math提出了PPO的改进算法GRPO
- V3详细介绍Infrastructure的搭建方法,并提出了高效FP8训练方法
- DeepSeek-V3
- 671B参数(37B激活),14.8T训练数据
- 基于V2的MoE架构,引入了MTP和新的复杂均衡损失
- 对于训练效率进行了极致优化,共使用2.788MH800GPU时
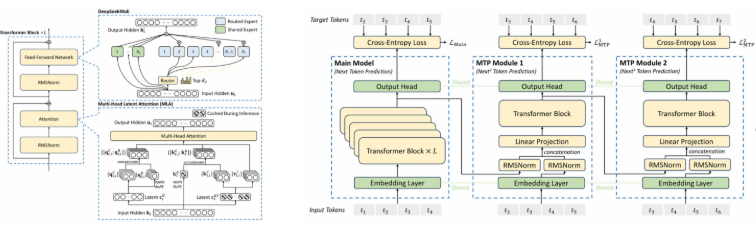
- DeepSeek-R1
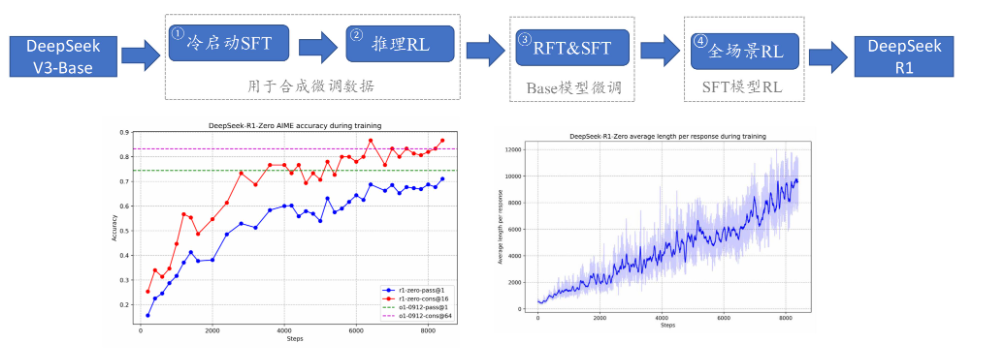
- DeepSeek-V3和DeepSeek-R1均达到了同期闭源模型的最好效果
- 开源模型实现了重要突破
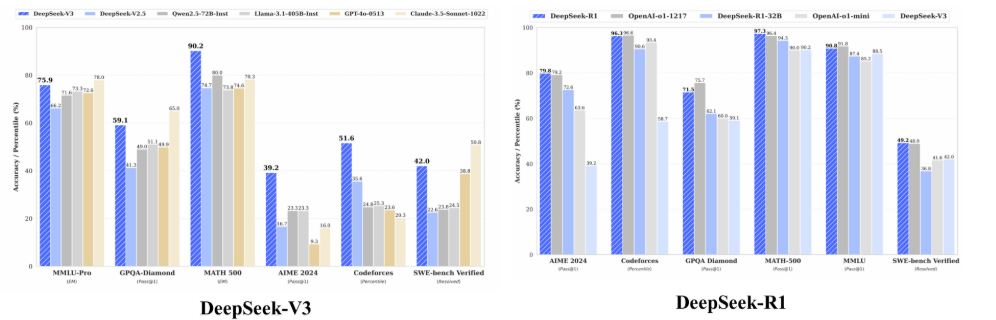
- 开源模型实现了重要突破
DeepSeek 的意义¶
- 为什么DeepSeek会引起世界关注
- 打破了OpenAI闭源产品的领先时效性
- 国内追赶GPT-4的时间很长,然而复现O1模型的时间大大缩短
- 达到了与OpenAI现有API性能可比的水平
- 中国具备实现世界最前沿大模型的核心技术
- 模型开源、技术开放
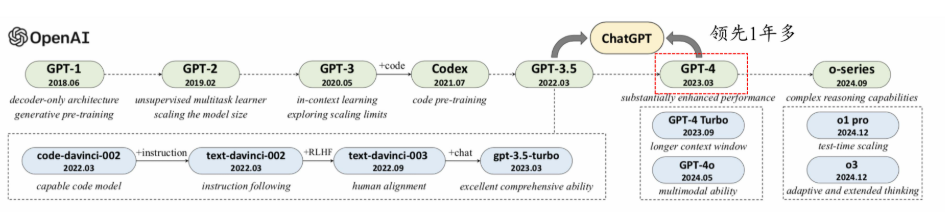
- 打破了OpenAI闭源产品的领先时效性
心得体会¶
GPT 的发展看起来是一个很漫长的过程,但是实际上也就几年的时间,Transformer 模型一开始仅仅是用于机器翻译上,谁也不会预料到他给我们的时代带来如此巨大转机。与此同时,中国的 LLM 发展也丝毫不落于美国,这也更加激励我们要把握时代风口,全民 ai 的时代很快就要到来了。与此同时,对于模型迭代的认知也是我们需要好好学习的经验。